Google BigQuery
Execute insert and query operations on Google BigQuery.
Google BigQuery is a fully managed, serverless data warehouse that enables super-fast SQL queries and real-time analytics over petabytes of data. See Google BigQuery for more details.
The Google BigQuery integration must be configured before using this node. See Google BigQuery Integration for more details.
Operations
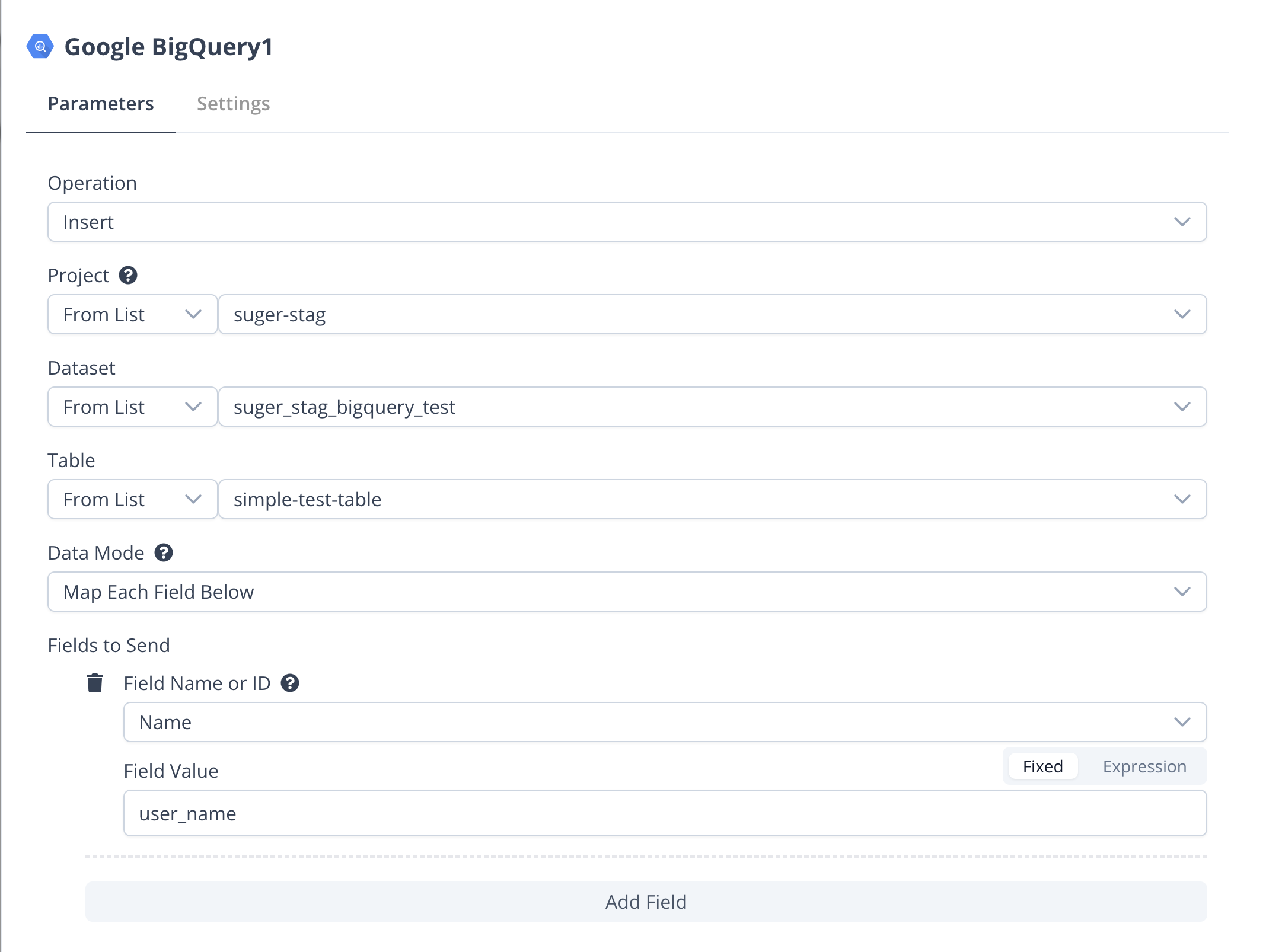
Insert
Parameters
- Project: Select or input the ID or URL of the project.
- Dataset: Select or input the ID of the dataset.
- Table: Select or input the ID of the table.
- Data Mode:
- Auto-Map Input Data: Used when the node input data properties match the table field names. In this mode, make sure the incoming data fields are named the same as the columns in BigQuery.
- Map Each Field Below: Define a mapping of the node input data properties to the table field names.
Options
- Batch Size: The number of rows to insert in each batch.
- Ignore Unknown Values: Whether to ignore row values that do not match the table schema.
- Skip Invalid Rows: Whether to skip rows with values that do not match the table schema.
- Template Suffix: Create a new table based on the destination table and insert rows into the new table. The new table will be named
${destinationTable}${templateSuffix} - Trace ID: Unique ID for the request, for debugging only. It is case-sensitive, limited to up to 36 ASCII characters. A UUID is recommended.
Execute Query
Parameters
- Project: Select or input the ID or URL of the project.
- SQL Query: The SQL query to execute. Standard SQL syntax is used by default, but you can also use Legacy SQL syntax by using the option ‘Use Legacy SQL’.
Options
- Default Dataset Name or ID: If not set, all table names in the query string must be qualified in the format ‘datasetId.tableId’.
- Dry Run: When set to true, BigQuery doesn’t actually run the job. Instead, if the query is valid, BigQuery returns statistics about the job such as how many bytes would be processed. If the query is invalid, an error returns.
- Include Schema in Output: Whether to include the schema in the output. If set to true, the output will contain key
_schemawith the schema of the table. - Location (Region): Location or the region where data would be stored and processed. Pricing for storage and analysis is also defined by location of data and reservations, more information about BigQuery locations.
- Maximum Bytes Billed: Limits the bytes billed for this query. Queries with bytes billed above this limit will fail (without incurring a charge). String in Int64Value format.
- Max Results: The maximum number of rows of data to return.
- Timeout: How long to wait for the query to complete in milliseconds.
- Raw Output: Whether to return the raw output of the query.
- Use Legacy SQL: Whether to use BigQuery’s legacy SQL dialect for this query. If set to false, the query will use BigQuery’s standard SQL.