Aggregate
Combine and process data from multiple inputs.
Overview
The Aggregate node is a powerful data processing tool that combines multiple input items into a consolidated output. It’s particularly useful when you need to merge data from different sources, extract specific fields, or combine lists from multiple items.
Operations
The Aggregate node supports two main modes of operation:
Individual Fields Aggregation
Aggregate specific fields from multiple input items with precise control over the output.
Configuration Options:
-
Field Selection:
- Source Field: The field to aggregate from input items
- New Field Name: Custom name for the aggregated field
- Dot Notation Support: Access nested fields (e.g., “user.name”)
-
Processing Options:
- Keep Missing Values: Include fields even if missing in some items
- Keep Only Unique: Remove duplicate values from the output
- Merge Lists: Combine arrays from different items
- Include Binaries: Option to include binary data
All Fields Aggregation
Combine all fields from multiple input items into a single output structure.
Configuration Options:
-
Destination Settings:
- Destination Field: Name of the field to store combined data (default: “data”)
- Include Fields: Specify fields to include in the aggregation
- Exclude Fields: Specify fields to exclude from the aggregation
-
Processing Options:
- Keep Missing Values: Include fields even if missing in some items
- Keep Only Unique: Remove duplicate values from the output
- Merge Lists: Combine arrays from different items
- Include Binaries: Option to include binary data
Common Use Cases
-
Data Consolidation
- Merge user data from multiple sources
- Combine related records into a single view
- Aggregate statistics or metrics
-
List Processing
- Merge arrays from different items
- Remove duplicates from combined lists
- Process nested data structures
-
Field Extraction
- Extract specific fields from multiple records
- Rename fields for better organization
- Handle complex nested data structures
Best Practices
-
Field Naming
- Use clear, descriptive names for output fields
- Avoid duplicate field names in the output
- Use dot notation carefully for nested structures
-
Data Processing
- Consider enabling “Keep Only Unique” when dealing with potential duplicates
- Use “Keep Missing Values” when all data points are important
- Be mindful of memory usage when processing large datasets
-
Performance
- Limit the number of fields when using All Fields Aggregation
- Use Individual Fields Aggregation for specific needs
- Consider the impact of binary data inclusion
Example
For example, if you have three input items with the following data(can generate using the Suger Code node):
[
{ "json": { "num": 1 } },
{ "json": { "num": 2 } },
{ "json": { "num": 3 } }
]You can configure the Aggregate node to combine these into a single output item with the following settings:
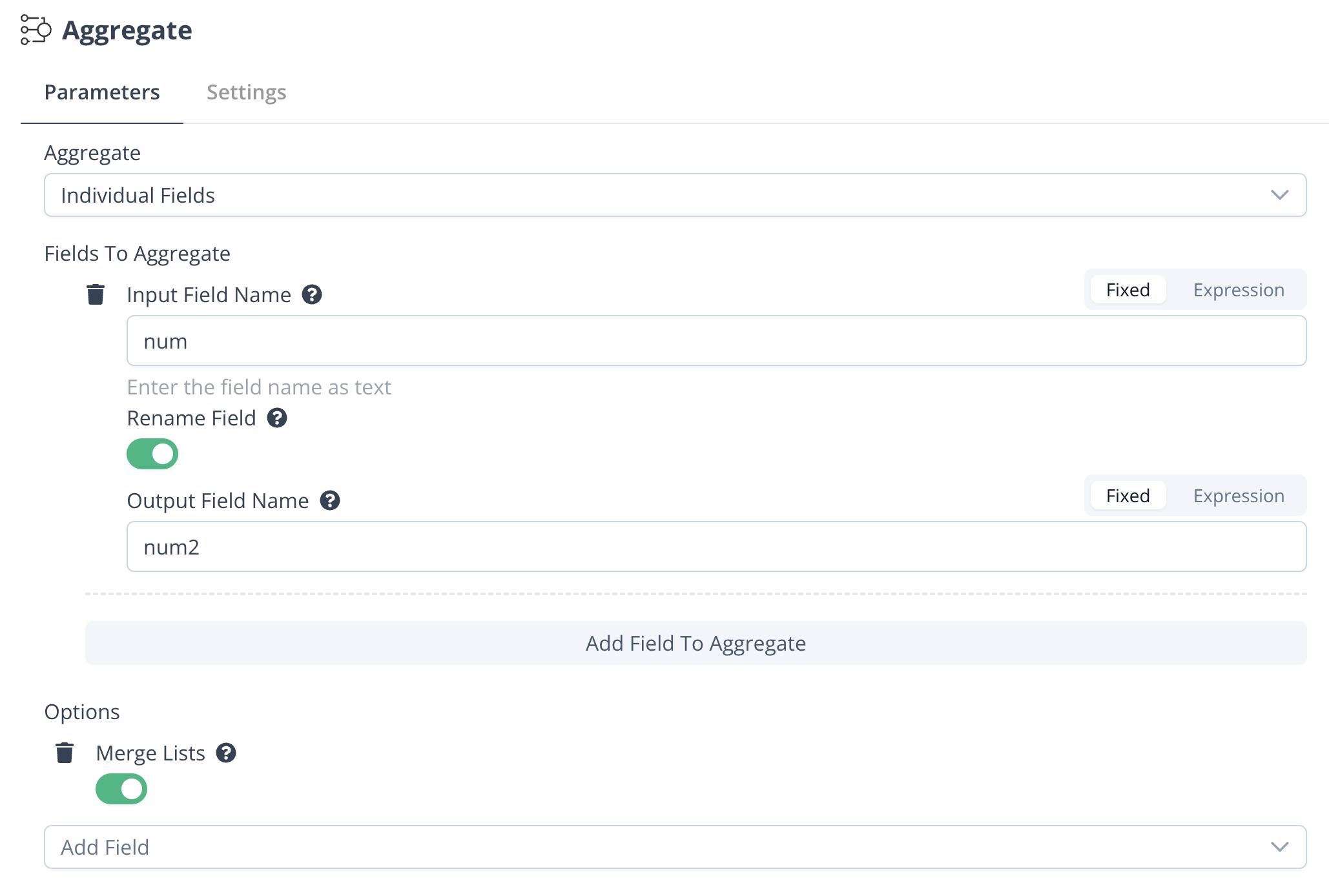
then, it will generate the following output:
[
{ "json": { "num2": [1, 2, 3] } }
]